
Paper link | Code link | AAAI 2024
增強式學習(Reinforcement Learning,RL)在序列生成模型中可能會導致高昂的計算成本。
本研究提出了一種有效的增強式學習方法(ESRL),使用兩階段和動態採樣的方式來提高效率。
將強化學習(Reinforcement Learning,RL)應用於序列生成模型可優化長期回報,例如 BLEU 分數和人類反饋。
然而,這通常需要對動作序列進行大量採樣,由於機器翻譯中的動作空間較大且序列較長,這在計算上具有挑戰性。
在本研究中,他們引入了兩階段採樣和動態採樣的方法,以提高這些模型在訓練過程中的採樣效率。
在訓練序列生成模型中,強化學習(Reinforcement Learning,RL)受到了關注,但由於動作空間大且序列長,在自然語言處理中的應用仍存在挑戰。
以下是傳統強化學習損失計算的示意圖。

為了解決這些挑戰,他們探索了在序列生成模型的強化學習中減少探索期間計算負載的策略。
在序列生成模型中,給定一個輸入 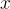 ,模型生成一個長度為
,模型生成一個長度為 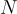 的 token 序列
的 token 序列 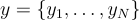 。在訓練過程中,模型學習概率:
。在訓練過程中,模型學習概率:
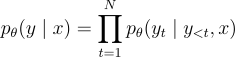
在推理階段,他們根據概率 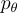 逐步生成token。
逐步生成token。
該訓練實例的強化學習損失為:
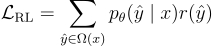
其中,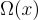 是輸入
是輸入 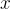 的所有可能候選目標序列的輸出空間。
的所有可能候選目標序列的輸出空間。
本研究的高效取樣強化學習(Efficient Sampling-based RL,ESRL)可以有效地進行探索。

為了解決取樣過程中計算圖存儲要求過高的問題,他們使用了兩階段框架。
在第一階段,他們使用自回歸模型來取樣候選序列。
在第二階段,他們計算這些取樣序列的概率。
本研究提出了一種動態取樣來進一步提高強化學習訓練的效率。
他們首先估計模型的能力,然後根據這個估計調整取樣大小和溫度,從而實現高效且充分的取樣。
本研究將標準策略方法替換為 MRT 和 REINFORCE 的融合來計算損失。
在他們的實驗中,他們使用了三個不同的任務,並使用標準的Transformer基本模型:
機器翻譯

抽象總結


 iThome鐵人賽
iThome鐵人賽